Big O for Noobs (by a noob) — Part I
Let me preface this post with…I’m still working on my problem solving skills and am improving how I code by trying to identify the time complexity of my code as I code.. And as the saying goes, the best way to learn is to teach, so stumble along with me as I work all this out in my head.
When first introduced to Big O, my brain went blank from simply trying to understand the definition. If you’re here, it probably happened to you too, but don’t fret, I’m hoping that you’ll have a clearer picture after reading this.
You’ve probably thought to yourself many times while writing code, is this the best way to do this? How can I improve this code? Why is this taking extra time to run? Questions like those is what Big O is supposed to help you answer. Sure we can create a an instance of a time object to get a timestamp before our code executes and after the execution then subtract to get the difference, but everybody has a different machine with difference specs so the time will change depending on which machine you run it on.
By definition(my definition), Big O is a way to express the rate of growth in terms of the amount of steps and space( memory) required as the amount of inputs, n, grows. A good analogy which I got from Cracking the Coding Interview is this:
You are in NYC, and want to transfer a file over to somebody else in LA, what would be the quickest way to do this? Would you put the file on a storage drive and fly to the person to hand it over, or mail it? The first thought that normally comes to mind is to send it over by email or put it up on a cloud service and have the other person download it. That makes sense if the file size is small enough, but what if you increase the file size(the input) to several Terabytes, that can take several days for the person to get it. In that case, flying there might be the better option, because it’ll always be approximately a 6hr flight.
Big O is normally expressed as O(whatever), the ‘whatever’ representing the rate of change.
O(1) means that no matter what you input into the function, it will pretty much take the same number of steps. In the case of the example above, flying the files over to LA.
O(n) means that any time the input grows, the number of steps will increase just as much. So if your filesize is 1gb and it takes 10 minutes to transfer, 2gb will end up taking 20 minutes to transfer and 3gb will take 30 minutes.
O(n²) means that any time your input grows, the number of steps will increase by the power of 2. So if your file size is 1gb and takes 10 minutes to transfer, a 2gb file will end up taking 40 minutes and 3gb will take a whopping 90 minutes. When you’re dealing with a lot of data, a function like this will run incredibly slow. You want to stay away from this as much as you can. This is normally the case for nested loops, if you can avoid it, stay away from nest loops!
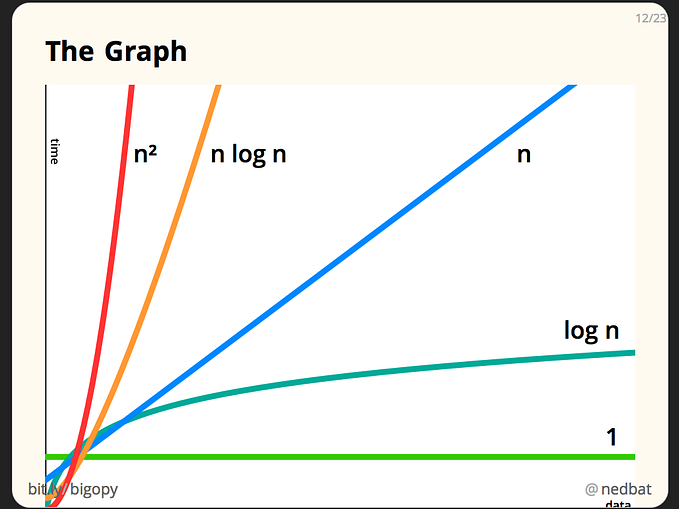
O(log n) it looks complicated especially if you haven’t brushed up on your math skills in a while, it’s really log2n, which means, how many times does 2 have to be multipled with itself to get n. So if n was 8, the answer would be 3 because…2 x 2 x 2 = 8, if n was 16, it would be 4. So if you follow the trend, rate of growth is that for every time you double n, the function only requires 1 more additional step, which means O(logn) is magical. Peep the graph below.

Okay, so how do we identify and apply this to code?
We can start by looking at the most basic data structure that comes with most languages — arrays(lists in python, but I’ll be explaining in Javascript), and identify the time complexity of the essential operations — read, insert, search, and delete. We can also analyze the complexities of the best-case and worst-case scenarios. In most part, when asked for the time complexity of a solution, you’ll be asked for the worst-case scenario, but it’s also good to know the best-case and average-case scenarios to select the best solutions to address the most common use cases.
Arrays
In memory, the elements of an array are stored sequentially in cells/memory addresses right next to each other.
An array may look like this,
const arr = [2,5,7,3,9,6,1,8,4].
Reading from an array always takes just one step O(1) — using arr[2] jumps right to the 2nd indexed cell and returns the 7.
Insertion is a little more complicated. If you write to the end of an array, just appending a value, it’s O(1), another cell allocated is filled with the new value.
arr[9] = 0
arr // [2,5,7,3,9,6,1,8,4,0]
But what happens when you insert to the beginning of the array with something like arr.unshift(10)? What then happens is that every element has to be shifted 1 spot over to make space for the 10 to be inserted, which translates to O(n). In the worst-case scenario, n number of elements have to be shifted before the insertion of the new element.
By searching, we mean looking for a value in the array. In order to do that, we’d have to loop through every element in order to do a comparison to find what we’re looking for. Take this example function for instance, it returns the index of a number or returns -1 if the number is not found.
In order to find an element, we have to search every cell for it and do a comparison. If the element happens to be the last element, we’d have to look at every single one, so in actuality it’s O(2n), but one of the rules for Big O is to drop constants because in the long run, the 2 is insignificant. So after dropping the 2, we get O(n). In a future post, we’ll take a look at binary search which is an algorithm for searching through sorted arrays which will be much faster.
Deleting elements in an array is pretty much the same as insertion, when you delete an element, you’ll have to shift the elements back to close up the void created by the deletion. If an element is deleted from the end, it’ll be O(1), the item will be gone and no shifting of elements requied. But if an element is deleted from the front — arr.shift(), n elements have to be shifted back, so this indicates that it’s O(n).
So far we’ve covered what the purpose of Big O is, the common notations to classify time complexity and applied them to the operations of an array. In the next post of this series, we’ll start looking at how to identify the time complexity for solutions to common problems. Thanks for reading and stay tuned!